Google presenta TurboQuant, capaz de reducir hasta 6 veces la memoria que necesitan los modelos de IA
La inteligencia artificial ha llegado como una nueva revolución tecnológica que sin duda está dando mucho de qué hablar debido a sus sorprendentes capacidades. Sin embargo, además de los retos de consumo de energía, ahora la cantidad de memoria necesaria para ejecutar modelos está provocando una grave escasez de memoria RAM y un aumento de precios.
Los modelos grandes (como los que alimentan ChatGPT, Gemini o Grok) necesitan muchísima RAM o memoria de video (VRAM) para funcionar, especialmente cuando recuerdan conversaciones largas o procesan información compleja.
Google Research ha presentado TurboQuant, una nueva técnica de compresión que promete cambiar eso. En pruebas, TurboQuant logra reducir la memoria necesaria en el “key-value cache” (la parte donde la IA guarda información temporal) en al menos 6 veces, y en algunos casos acelera el procesamiento hasta 8 veces. Todo sin perder calidad ni precisión.
¿Cómo funciona TurboQuant?
Los investigadores usaron algoritmos avanzados de cuantización (bajar la precisión de los números sin que se note) combinados con rotaciones inteligentes de datos y un método llamado Quantized Johnson-Lindenstrauss. El resultado es que la IA necesita menos espacio para tomar apuntes mientras piensa, pero sigue respondiendo igual de bien.
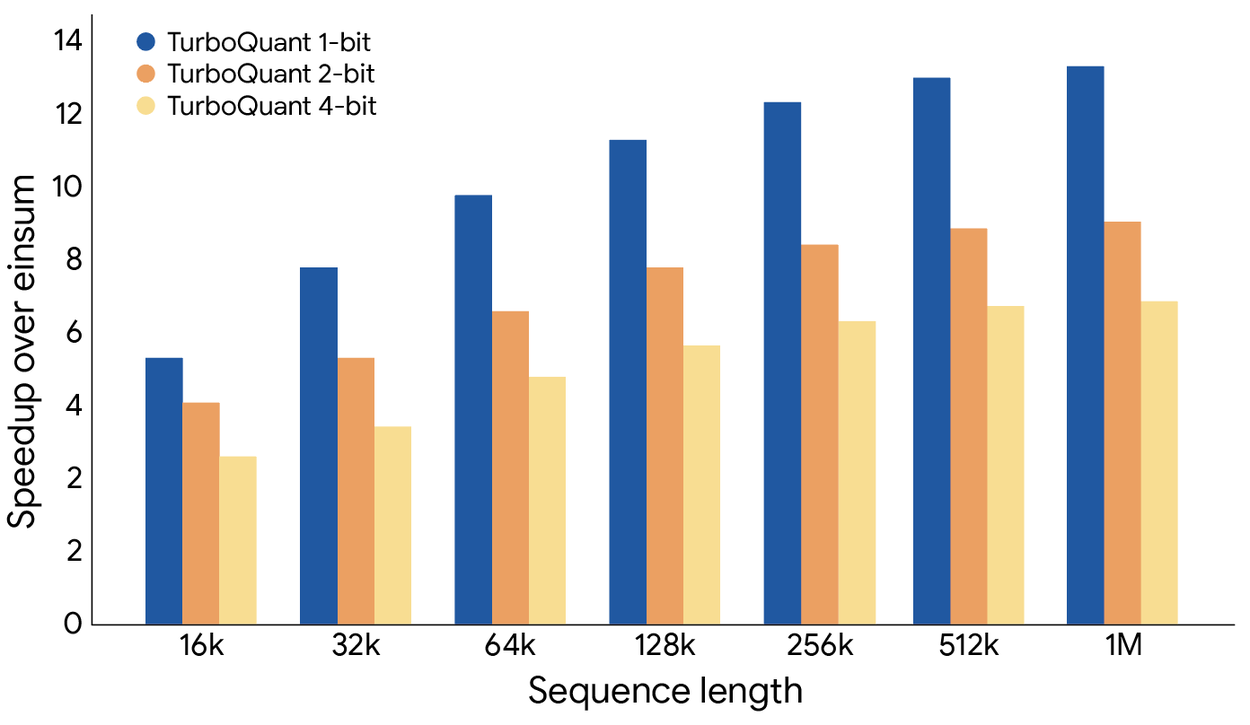
El anterior gráfico ilustra la aceleración en el cálculo de logits de atención usando TurboQuant: específicamente, TurboQuant de 4 bits logra hasta un aumento de rendimiento de hasta 8 veces más que las claves no cuantizadas de 32 bits en aceleradores de GPU H100 de NVIDIA.
Este hito ha sido ampliamente destacado al lograr hacer que correr modelos de IA sea más barato (menos servidores o GPUs caras), al tiempo que permite llevar IA más potente en dispositivos con menos memoria como celulares, laptops o en edge computing). Todo eso con una reducción del consumo energético de los data centers.
Tras el anuncio, las acciones de fabricantes de memoria (como Samsung, Micron y SK Hynix) bajaron, porque si se necesita menos memoria para lo mismo, la demanda podría bajar un poco.
Para el usuario común, esto se vería reflejado en respuestas más rápidas y, probablemente, precios más bajos en servicios de IA.
TurboQuant se presentará en la conferencia ICLR 2026 y es un avance que cualquier empresa podría implementar. Google lo describe como una forma de hacer que la IA sea más accesible y sostenible.
Relacionados